مسیریابی مبتنی بر یادگیری در رباتیک

در دنیای پرسرعت رباتیک، مسیریابی—محاسبهی یک مسیر بدون برخورد از وضعیت شروع تا هدف—بهطور سنتی بر الگوریتمهای مدلمحور صریحی مانند A*، درختهای کاوش تصادفی سریع (RRT) و نقشههای احتمالی راهنما (PRM) تکیه داشته است. هرچند…
در دنیای پرسرعت رباتیک، مسیریابی—محاسبهی یک مسیر بدون برخورد از وضعیت شروع تا هدف—بهطور سنتی بر الگوریتمهای مدلمحور صریحی مانند A*، درختهای کاوش تصادفی سریع (RRT) و نقشههای احتمالی راهنما (PRM) تکیه داشته است. هرچند این برنامهریزهای کلاسیک تضمینهای نظری از کامل بودن و بهینگی تحت شرایط مشخص را ارائه میدهند، اما معمولاً در فضاهای پیکربندی با ابعاد زیاد، محیطهای پویا یا نیمهناشناخته و وظایفی که نیازمند سازگاری بلادرنگ هستند، دچار مشکل میشوند. مسیریابی مبتنی بر یادگیری پارادایمی قدرتمند است که از تکنیکهای دادهمحور—از شبکههای عصبی عمیق تا یادگیری تقویتی—برای غلبه بر این محدودیتها بهره میگیرد. با یادگیری نمایههای محیط و خطمشیهایی برای تولید مسیرها، برنامهریزهای مبتنی بر یادگیری میتوانند به سناریوهای جدید سازگار شوند، به فضاهای پیچیده مقیاسپذیری یافته و عملکرد بلادرنگ را محقق کنند. این پست وبلاگی یک بررسی جامع و عمیق از مسیریابی مبتنی بر یادگیری در رباتیک ارائه میدهد. ابتدا مبانی مسیریابی را مرور کرده و رویکردهای مدلمحور را با رویکردهای مبتنی بر یادگیری مقایسه میکنیم. سپس به تکنیکهای اصلی یادگیری ماشین—شامل یادگیری نظارتشده، یادگیری با تقلید و یادگیری تقویتی—میپردازیم که زیرساخت برنامهریزهای مبتنی بر یادگیری هستند. پس از آن، انتخابهای معماری کلیدی مانند شبکههای عصبی پیچشی و گرافی را بررسی کرده و سیستمهای نمونهای را معرفی میکنیم. در پایان، کاربردهای واقعی، چالشهای پیشِ رو و جهتهای آینده در این حوزه پرجنبوجوش را بحث خواهیم کرد.
۱. مبانی مسیریابی رباتیک
۱.۱ فضای پیکربندی و برنامهریزی حرکت
هر سامانهی رباتیک را میتوان با فضای پیکربندی (C-space) توصیف کرد؛ فضایی که ابعاد آن متناظر با پارامترهای مستقل (مانند زوایای مفصل برای بازوها یا (x, y, θ) برای رباتهای متحرک) است. مسیریابی عبارت است از یافتن یک منحنی پیوسته در C-space که از وضعیت شروع به هدف برسد و از نواحی ممنوعه ناشی از موانع عبور نکند. برنامهریزهای کلاسیک C-space را گسسته (مانند شبکهها در A*) یا نمونهبرداریشده (مانند RRT) مدلسازی کرده و با جستجوی گراف مسیر قابلقبول را مییابند.
محدودیتهای برنامهریزهای کلاسیک
-
مقیاسپذیری: تعداد نمونهها یا سلولهای شبکه با ابعاد C-space بهصورت نمایی افزایش مییابد («نفرین بُعد»)، که باعث هزینهی محاسباتی زیاد بهویژه با افزایش درجه آزادی ربات میشود.
-
دینامیک و عدم قطعیت: برنامهریزهای مدلمحور محیطهای استاتیک و کاملاً مشاهدهشده را فرض میکنند و برای بازبرنامهریزی در مواجهه با موانع متحرک یا نیمهناشناخته بهصورت مکرر و پرهزینه عمل میکنند.
-
تنظیم حکمها: بسیاری از برنامهریزها روی حکمها یا توابع هزینهی از پیش تنظیمشده تکیه دارند که در هنگام انتقال به محیطها یا وظایف جدید ناپایدار و شکننده هستند.
برنامهریزهای مبتنی بر یادگیری با جابجایی از جستجوی صریح روی C-space به نگاشتهای یادگرفتهشده که قادر به تعمیم از تجربههای گذشته هستند، این محدودیتها را برطرف میکنند.
۲. پارادایمهای یادگیری برای مسیریابی
سه پارادایم اصلی یادگیری در رباتیک مورد بررسی قرار گرفته است:
۲.۱ یادگیری نظارتشده
رویکرد: از یک مجموعهداده حاوی نمایههای محیط (مانند نقشههای اشغال، ابرنقاط یا تصاویر) جفتشده با مسیرهای بهینه یا نزدیک بهینه استفاده میشود تا مدلی—اغلب شبکهی عصبی عمیق—آموزش ببیند و بهطور مستقیم مختصات یا فرمانهای کنترلی را پیشبینی کند.
-
تولید داده: مسیرها میتوانند بهصورت پیشین با استفاده از برنامهریزهای کلاسیک در شبیهسازها تولید و بهعنوان برچسب به کار روند.
-
معماریها: شبکههای عصبی پیچشی (CNN) برای ورودیهای تصویری؛ پرسپترونهای چندلایه (MLP) برای ویژگیهای کمبعدی؛ شبکههای عصبی گرافی (GNN) برای نمایههای گرافی.
-
مزایا و معایب: مدلهای نظارتشده میتوانند در سناریوهای جدید مسیرها را سریع پیشبینی کنند، اما عملکرد آنها به کیفیت و تنوع مجموعهداده آموزشی بستگی شدید دارد و در مواجهه با محیطهای خارج از توزیع آموزش دچار مشکل میشوند.
۲.۲ یادگیری با تقلید (تقلید رفتار)
رویکرد: که به آن «تقلید رفتار» نیز گفته میشود، این تکنیک مسیریابی را بهعنوان یک وظیفهی تقلیدی در نظر میگیرد: مدل یاد میگیرد تصمیمهای یک کارشناس (مانند اپراتور انسانی یا برنامهریز کلاسیک بهینه) را با کمینهسازی فاصله بین عملهای کارشناس و پیشبینیهای مدل تقلید کند.
-
مزایا: نیازی به تعریف صریح تابع پاداش نیست و میتوان از نمایشهای انسانی برای یادگیری رفتارهای ظریف استفاده کرد.
-
محدودیتها: در معرض انحراف توزیع ورودی قرار دارد: انحرافهای کوچک از مسیرهای نمایشدادهشده میتواند مدل را به وضعیتهای ناآشنا ببرد و خطاها بهتدریج تجمع یابند. تکنیکهایی مانند DAgger (جمعآوری دادهی رویسیاست) و بازخورد تصحیحی میتوانند با جمعآوری دادههای جدید تا حدی این مشکل را کاهش دهند.

۲.۳ یادگیری تقویتی
رویکرد: یادگیری تقویتی مسیریابی را بهعنوان یک مسئلهی تصمیمگیری متوالی میبیند، جایی که ربات (عامل) با گرفتن عملها (مانند فرمانهای سرعت) با محیط تعامل میکند و پاداش دریافت میکند (مثلاً هزینهی منفی برای برخورد و پاداش مثبت برای رسیدن به هدف). هدف، یادگیری خطمشیای است که مجموع پاداش تجمعی را بیشینه کند.
-
RL بدون مدل: الگوریتمهایی مانند DQN، SAC یا PPO بدون نیاز به مدل صریح محیط، مستقیماً از تعاملات سیاست یا تابع ارزش را میآموزند.
-
RL مدلمحور: از یک مدل آموختهشده یا تقریبِ مدلِ دینامیک محیط برای برنامهریزی در فضای نهان (مانند کنترل پیشبین مدل همراه با دینامیک آموختهشده) بهره میبرد.
-
بهرهوری نمونه و ایمنی: RL اغلب نیازمند تعاملات بسیار زیاد با محیط است؛ تکنیکهایی مانند بافرهای تکرار غیرسیاستی، یادگیری برنامهریزیشده (curriculum learning)، تصادفیسازی حوزه و انتقال شبیهسازی به دنیای واقعی میتوانند بهرهوری و تعمیمپذیری را بهبود بخشند.
۳. اجزای معماری کلیدی
۳.۱ شبکههای عصبی پیچشی (CNN)
CNN ها برای پردازش ورودیهای ساختار شبکه—مانند نقشههای اشغال یا تصاویر عمق—مناسباند. یک برنامهریز مبتنی بر CNN معمولاً یک تصویر اشغال محلی یا سراسری را دریافت کرده و یا:
-
نقطههای میانی (waypoints): مجموعهای از اهداف میانی را پیشبینی میکند تا یک کنترلکنندهی سطح پایین آنها را دنبال کند.
-
خطمشی فرمان: فرمانهای مستقیم سرعت یا شتاب را در هر گام زمانی تولید میکند.
ملاحظات کلیدی شامل عمق شبکه، حوزهی دید (receptive field) برای درک وابستگیهای بلندبرد و تلفیق ویژگیهای چندمقیاس برای ادغام اجتناب محلی و هدفگذاری سراسری است.
۳.۲ شبکههای عصبی گرافی (GNN)
زمانی که محیط بهطور طبیعی به صورت گراف نمایش داده میشود (مانند گرههایی برای نقاط اتصال یا تقاطع)، GNN ها میتوانند عملیات انتقال پیام یادگرفتهشدهای را اجرا کنند که اطلاعات مربوط به ریسک برخورد، فاصلهها و امکانپذیری را گسترده میکند. GNN ها به برنامهریزها اجازه میدهند:
-
تجمیع هزینهی یادگرفتهشده در لبههای گراف را انجام دهند.
-
به ساختارهای گرافی جدید که در آموزش دیده نشدهاند تعمیم یابند.
-
اطلاعات معنایی (مانند هزینههای عبور و احتمال موانع متحرک) را ادغام کنند.
۳.۳ مکانیزمهای بازگشتی و توجه
مسیریابی ذاتاً یک تصمیمگیری متوالی است. شبکههای عصبی بازگشتی (RNN) یا معماریهای مبتنی بر توجه (Transformer) میتوانند دادههای سریزمانی حسگر (مانند اسکنهای LiDAR در طول زمان) را پردازش و مشاهدات گذشته را برای پیشبینی عملهای آینده به خاطر بسپارند. لایههای توجه به مدل کمک میکنند روی نواحی مهم—مانند گذرگاههای باریک یا موانع متحرک—تمرکز کند.
۴. سیستمهای نمونه و مطالعات موردی
۴.۱ Neural RRT: یادگیری توزیع نمونهها
RRT ها بر نمونهبرداری یکنواخت در C-space تکیه دارند که در محیطهای شلوغ ناکارآمد است. Neural RRT با افزودن یک نمونهبردار یادگرفتهشده—شبکهی عصبی که مناطق امیدوارکننده برای نمونهبرداری را بر اساس چیدمان موانع پیشبینی میکند—کاوش را به سمت گذرگاههای باریک یا نواحی با ارزش هدایت میکند. نتایج تجربی نشاندهندهی کاهش چشمگیر زمان برنامهریزی و بهبود کیفیت مسیر در وظایف حرکتی با ابعاد بالا است.
۴.۲ ChauffeurNet: خطمشی رانندگی انتهابهانتها
توسط Waymo توسعه یافته، ChauffeurNet از شبکهی کاملاً پیچشی آموزشدیده با تقلید رفتار بر روی میلیونها مایل رانندگی انسانی بهره میبرد. با دریافت نمای بالا (raster) از محیط اطراف خودرو، نقاط آینده و سرعت را پیشبینی میکند. نکتهی کلیدی، آموزش با تصحیحات رویسیاست است: برهمکنشهای شبیهسازیشده انحراف را ایجاد میکنند و پاسخهای اصلاحی کارشناس را ثبت میکنند تا از انحراف توزیع جلوگیری شود. ChauffeurNet عملکرد پایداری در سناریوهای پیچیده شهری با بازیگران پویا نشان داده است.
۴.۳ شبکههای ارزشیابی انتگرالی (VIN)
VINها یک برنامهریز قابل تفکیک را در لایههای مخفی یک شبکهی پیچشی تعبیه میکنند. شبکه یاد میگیرد که با استفاده از مدل انتقال و نقشهی پاداشِ یادگرفتهشده (هر دو بهصورت هستههای پیچشی) بهطور انتگرالی مقدار تابع ارزش و خطمشی بهینه را محاسبه کند. این معماری به شبکه اجازه میدهد تا رفتارهای برنامهریزی را به محیطهای شبکهای و چیدمانهای موانع ندیده تعمیم دهد.
۴.۴ برنامهریز محلی گرافی با GNN
در اتوماسیون انبار، مسیریابی محلی در اطراف قفسهها را میتوان بر روی گراف تقاطعهای راهروها مدلسازی کرد. یک GNN آموزش میبیند تا هزینه و امکانپذیری هر لبهی گراف را پیشبینی کند، با در نظر گرفتن عواملی مانند ترافیک انسانی پویا و چیدمان متغیر قفسهها. وزنهای گرافی یادگرفتهشده سپس توسط جستجوی دایکسترا یا A* برای تولید مسیر نهایی استفاده میشوند و به این ترتیب سازگاری دادهمحور با تضمینهای کامل بودن جستجوی گرافی ترکیب میشود.
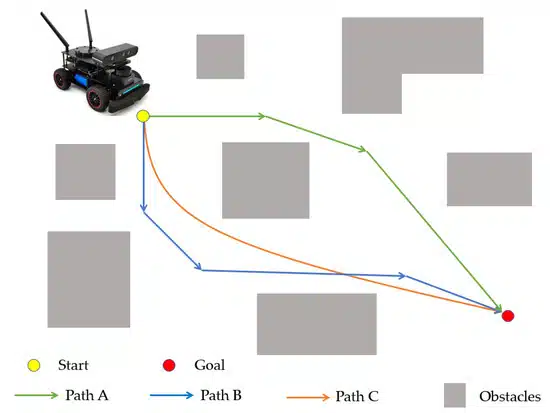
۵. کاربردها و استقرار واقعی
برنامهریزهای مبتنی بر یادگیری در پلتفرمهای رباتیکی متنوعی به کار رفتهاند:
-
وسایل نقلیه خودران: برنامهریزهای انتهابهانتها و سلسلهمراتبی برای حرکت در بزرگراه، رانندگی شهری و پارک کردن.
-
دستکاری (Manipulation): مسیریابی با ابعاد بالا برای بازوهای چندمفصلی در مونتاژ صنعتی، جابجایی قطعات و رباتهای جراحی.
-
رباتهای هوایی: اجتناب بلادرنگ از موانع و مانورهای تهاجمی برای پهپادها در محیطهای مملو از موانع.
-
رباتهای خدماتی: ناوبری در فضاهای داخلی دارای جمعیت انسانی با ادغام محدودیتهای اجتماعی (مانند نرمی مسیر و فضای شخصی).
-
زیرآبی ROVها: برنامهریزی در محیطهای زیرآبی با مشاهدهی ناقص و دادههای حسگر پراکنده.
برای استقرار موفق، اغلب از خط لولههای آموزش قوی با اجزای زیر استفاده میشود:
-
انتقال شبیهسازی به واقعیت: بهرهگیری از شبیهسازهای واقعی و تصادفیسازی حوزه برای پر کردن شکاف واقعیت.
-
محدودیتهای ایمنی: ادغام لایههای ایمنی (مانند ماژولهای تأیید و برنامهریزهای پشتیبان) برای مواجهه با سناریوهای خارج از توزیع.
-
سازگاری آنلاین: چارچوبهای یادگیری پیوسته که خطمشی را بر اساس تجربهی دنیای واقعی بدون فراموشی فاجعهآمیز بهبود میبخشند.
۶. چالشها و مسائل باز
با وجود پیشرفتهای چشمگیر، مسیریابی مبتنی بر یادگیری با چالشهایی روبهروست:
-
تعمیمپذیری: مدلهای آموزشدیده در مجموعهای از محیطها ممکن است در محیطهای ساختاری یا بصری متفاوت شکست بخورند. توسعهی برنامهریزهایی که بهطور مقاوم تعمیم یابند هنوز مسئلهای باز است.
-
بهرهوری نمونه: روشهای RL اغلب به میلیونها تعامل نیاز دارند که در دنیای واقعی عملی نیست. پیشرفت در RL مدلمحور و رویکردهای ترکیبی نظارتشده/RL در حال بهبود این وضعیت هستند، اما کار بیشتری لازم است.
-
تضمینهای ایمنی: برخلاف برنامهریزهای کلاسیک با تضمینهای صریح اجتناب از برخورد، برنامهریزهای یادگرفتهشده احتمالاً بهصورت احتمالاتی عمل میکنند و ممکن است بهطور غیرقابلپیشبینی شکست بخورند. ادغام روشهای رسمی یا تأیید ایمنی مسئلهای کلیدی است.
-
قابلتفسیر بودن: فهم تصمیمهای برنامهریزهای یادگرفتهشده—بهویژه شبکههای عصبی عمیق—چالشبرانگیز است. ابزارهای تفسیر و معماریهای شفاف برای رفع اشکال و صدور گواهینامه ضروریاند.
-
مقیاسپذیری به ابعاد بالا: باوجود کاهش بعضی بارهای محاسباتی توسط یادگیری، مقیاسپذیری به رباتهایی با بیش از ۲۰ درجه آزادی (مانند انساننماها) همچنان چالشهای معماری و آموزشی را پیش میکشد.
۷. جهتهای آینده
تقاطع مسیریابی و یادگیری ماشین همچنان زمینهای پربار برای نوآوری است. جهتهای آیندهی امیدوارکننده شامل:
-
برنامهریزی سلسلهمراتبی و ماژولار: ترکیب برنامهریزهای استراتژیک سطحبالا با کنترلکنندههای یادگرفتهشدهی سطحپایین برای تجزیه وظایف پیچیده و بهبود مقیاسپذیری.
-
متا-یادگیری برای سازگاری سریع: روشهای متا-یادگیری و یادگیری با چندنمونه (few-shot) که برنامهریزها را قادر میسازند با حداقل دادهی جدید سریعاً به محیطهای جدید سازگار شوند.
-
هماهنگی چندعامله: برنامهریزهای مبتنی بر یادگیری که میتوانند هماهنگی و اجتناب از برخورد میان چند ربات یا وسیله نقلیه را در فضاهای مشترک مدیریت کنند.
-
جمعآوری خودنظارتی داده: خط لولههای خودکار که به رباتها اجازه میدهند با کاوش دادههای آموزشی خود را برچسبگذاری کنند و وابستگی به نمایشهای انسانی یا شبیهسازهای دستی را کاهش دهند.
-
گواهینامه ایمنی-انتقادی: توسعهی چارچوبهایی برای تأیید رسمی برنامهریزهای یادگرفتهشده، با ترکیب انعطافپذیری دادهمحور و محدودیتهای ایمنی قابل اثبات.
نتیجهگیری
مسیریابی مبتنی بر یادگیری پارادایم مهمی در نحوهی ناوبری و دستکاری رباتها در محیطهای پیچیده ایجاد کرده است. با بهرهگیری از قدرت یادگیری عمیق، یادگیری تقویتی و نگاشتهای گرافی، این رویکردها سازگاری، سرعت و توانایی پردازش سناریوهایی را ارائه میدهند که برنامهریزهای کلاسیک قادر به حل آنها نیستند. اگرچه چالشهایی مانند تعمیمپذیری، ایمنی و تفسیرپذیری باقی است، سرعت بالای پژوهش—و استقرار موفق در حوزههایی از رانندگی خودران تا رباتهای جراحی—نشاندهندهی نوید عظیم این حوزه است. با ورود رباتها به زندگی روزمره، مسیریابی مبتنی بر یادگیری هستهی فناوریهای آینده برای سامانههای هوشمند، چابک و ایمن خواهد بود.





